Eighth Conference on Digital Humanities and Digital History · C²DH, University of Luxembourg
Beyond Keywords
AI-Mediated Access to the Islam West Africa Collection through an MCP Server and Agent Skill
 Scan for these slidesslides.frederickmadore.com
Scan for these slidesslides.frederickmadore.com
The Islam West Africa Collection (IWAC)
An open archive, built by one historian
Fifteen years of fieldwork and library work — Benin, Burkina Faso, Côte d'Ivoire, Togo — turned into an open-access collection.
- Mostly newspaper clippings and Islamic publications: magazines, brochures, tracts
- Behind it, a personal library of 30,000+ Zotero items
- Online at islam.zmo.de
Six countries · mostly French — also Arabic & Hausa · open access since 2023
The Islam West Africa Collection (IWAC)
An overview of the collection
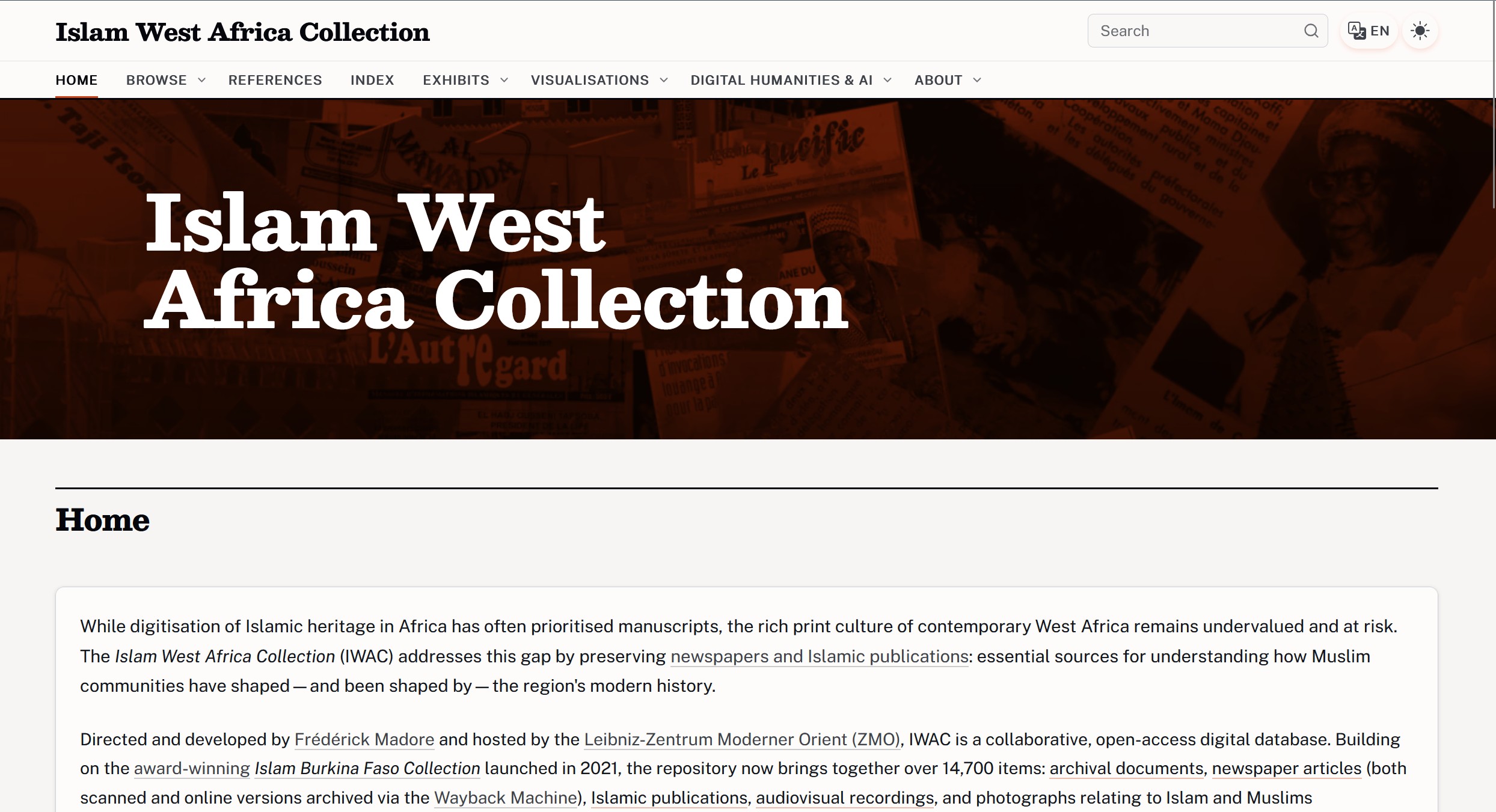
The "El Hadj" problem
Why keyword search falls short
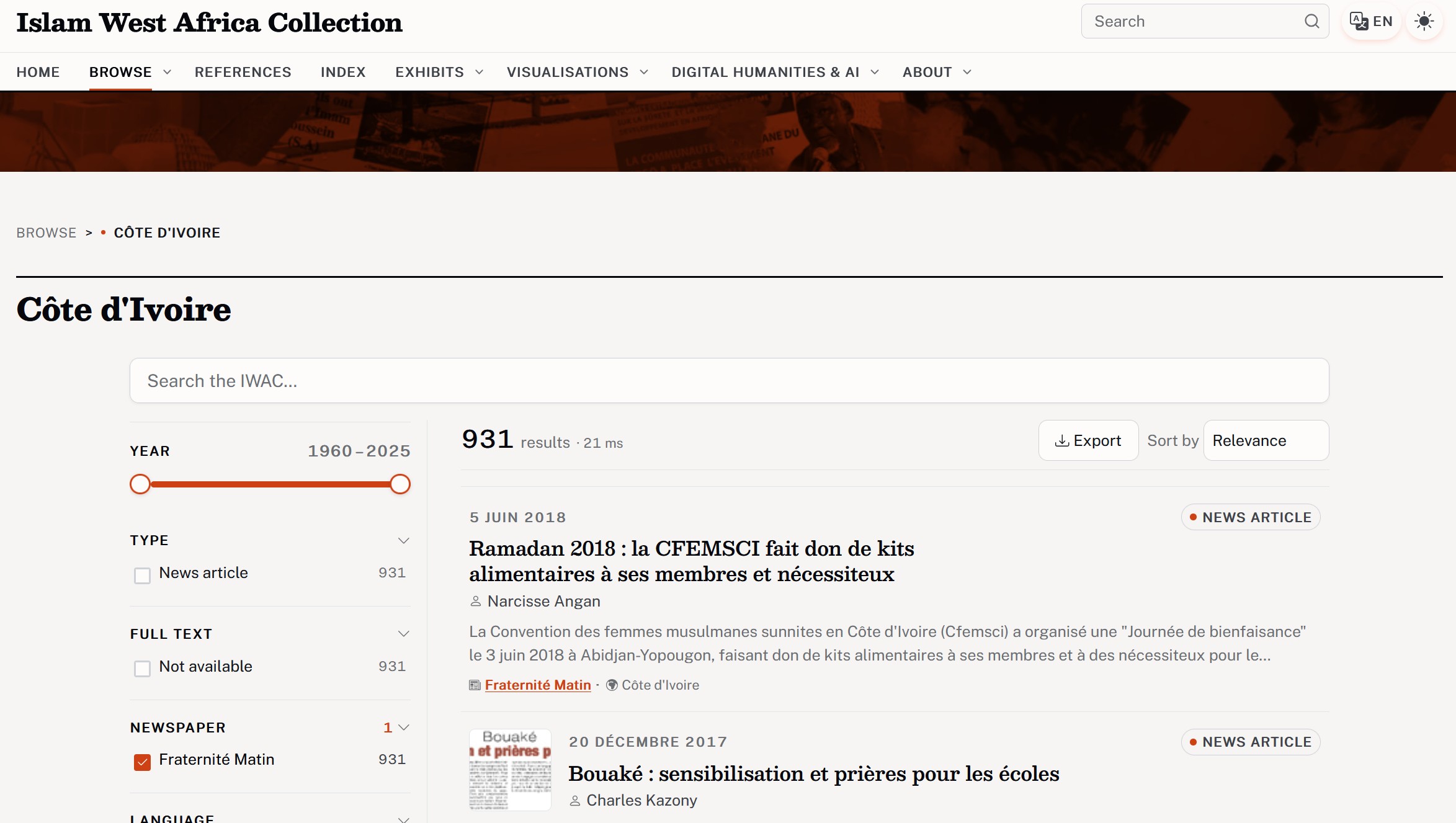
The faceted search of the IWAC.
Keyword search has built-in problems. I mitigated what I could:
- Spelling variants → authority files merge 20+ forms
- Forming a query → autocomplete and facets guide you
- Polysemy → "hadj" = pilgrimage and the "El Hadj" honorific
Why not just ask AI?
Generic answers, dubious sources
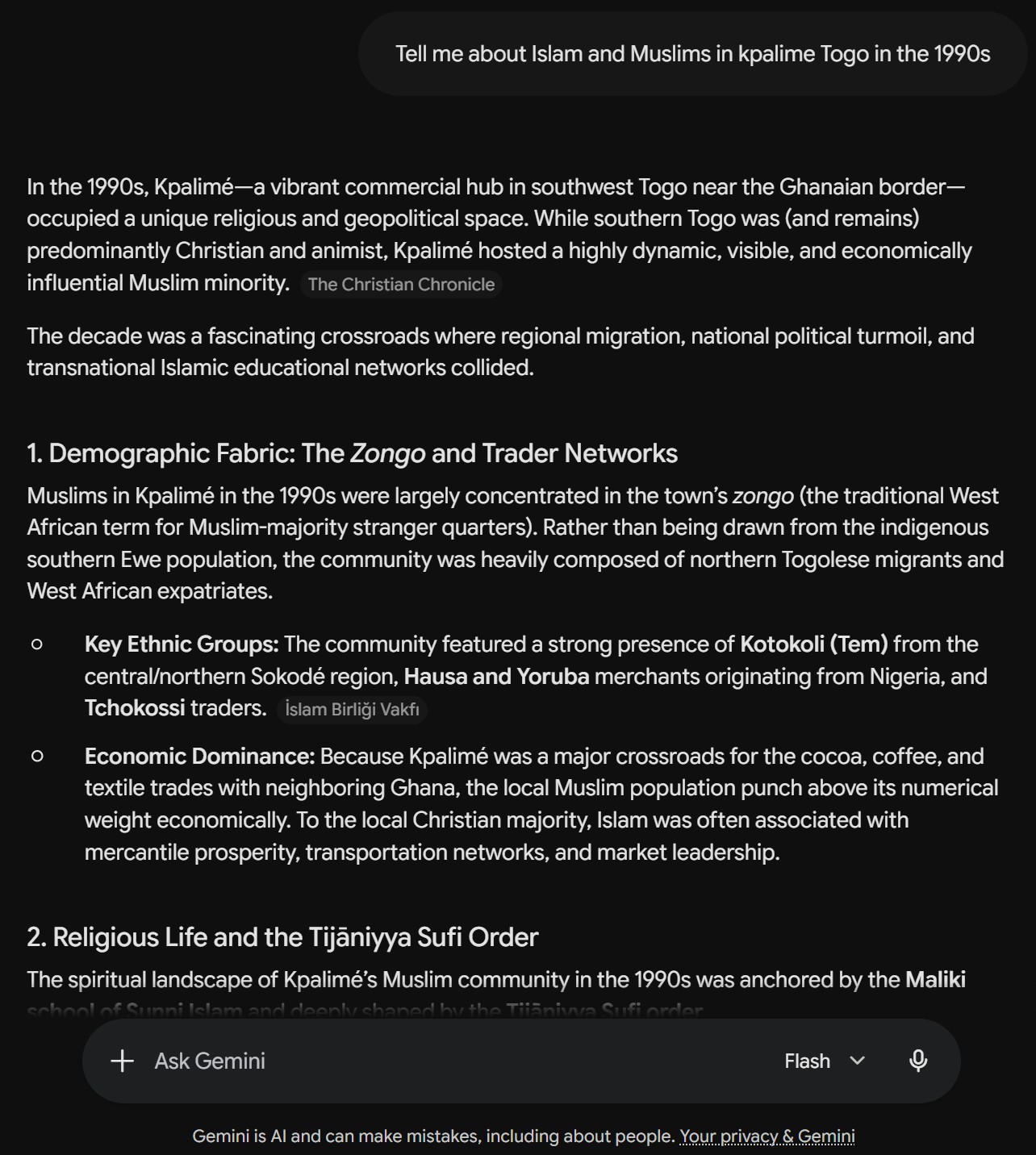
Gemini on Islam in Kpalimé: generic and dubiously sourced. See the chat ↗
- People now ask AI directly, not a search box
- Chatbots often invent citations — worse for Africa, with far less training data
- Web search helps, but the sources are often random
- The IWAC? Crawled by AI bots, yet barely used and badly cited
An approach
Two layers: plumbing and intelligence
Structured, read-only access to the collection that any AI assistant can call.
The methodology for using it well — a historian's method, written down.
Model Context Protocol · open standard, Nov 2024
Why a server, not just a chatbot?
An MCP server connects an AI assistant to one outside system. Like an app to your accounts:
Retrieval-augmented generation. Proven for GLAM, but it chunks records, and retrieves by a similarity the user never sees.
Ingests nothing. The data stays put; the server holds the logic; the model just asks and answers. modelcontextprotocol.io
Agent skills
What is a skill.md?
A skill is a methods handbook for a machine reader — loaded only when a request matches its purpose.
- Competence by reading, not retraining
- Versioned, reviewed, refined — a prompt is typed once and lost
- An open standard across agents — no vendor lock-in, like MCP
- Born in coding agents — the format fits any domain
my-skill/
├── SKILL.md # Required: metadata + instructions
├── scripts/ # Optional: executable code
├── references/ # Optional: documentation
├── assets/ # Optional: templates, resources
└── ... # Any additional files or directoriesThe standard layout of an agent skill — SKILL.md is the only required file.
What you can ask it
The IWAC MCP server
- "Newspaper articles on Islam in Abidjan, in the 1990s" articlesplace · period
- "Islamic publications on secularism in Togo and Benin" publicationssubject · country
- "Academic references on Muslim women in Burkina Faso" referencessubject · country
One plain-language request; the model picks the tools and combines the filters.
- Read-only: search, full text, authority records, sentiment, stats
- Verifiable: every call a lookup, no AI at query time
- Traceable: every result links to its canonical record
- Two ways in: one-click for Claude Desktop, a hosted URL for ChatGPT
Inside the server · semantic search
Search by meaning, not words
« Islam et laïcité au Burkina Faso »
Plain language — and any language works.
An embedding model (Gemini) maps the text to 768 numbers — one point in a space of meaning.
laïcité → [0.07, -0.12, 0.93, …]Every article was mapped the same way, in advance.
Cosine similarity ranks all 12,000+ articles by how close they sit — closest in meaning, not in wording.
Search the collection · offline demo
Keyword vs. meaning — in the slide itself
Dozens of articles are about secularism but never type the word — schooling, family-code debates, the Arabic press. Keyword search cannot see them. Click By meaning.
None contain the word laïcité — all are about the idea, including the Arabic record keyword search would never reach. · illustrative slice
The IWAC skill in motion
A five-phase research method
Two depths, chosen up front:
- Scoping — what does the collection even hold for this question, before any keyword?
- Systematic searching — French + transliteration variants (Tabaski = Eid al-Adha); log every search, including null results
- Deep reading — full text and sentiment, article by article
- Triangulation — cross-check articles, publications, references, index entries
- Synthesis — findings with source attribution and confidence grades
What a server never could
Discipline, disclosure — and a new role
- Linguistic discipline — search the French corpus in French, whatever language the question is in
- Bias disclosure — every synthesis states the skew: francophone tilt, missing Arabisants, thin Niger and Nigeria
- Evidential discipline — claims tagged primary / secondary / AI-derived; absence of evidence ≠ evidence of absence
The curator's method, in full
iwac-mcp · SKILL.md
Loading the skill file…Scroll to read the whole file — 190 lines, open source at github.com/fmadore/iwac-mcp-server
Live demo
From a plain question to cited sources
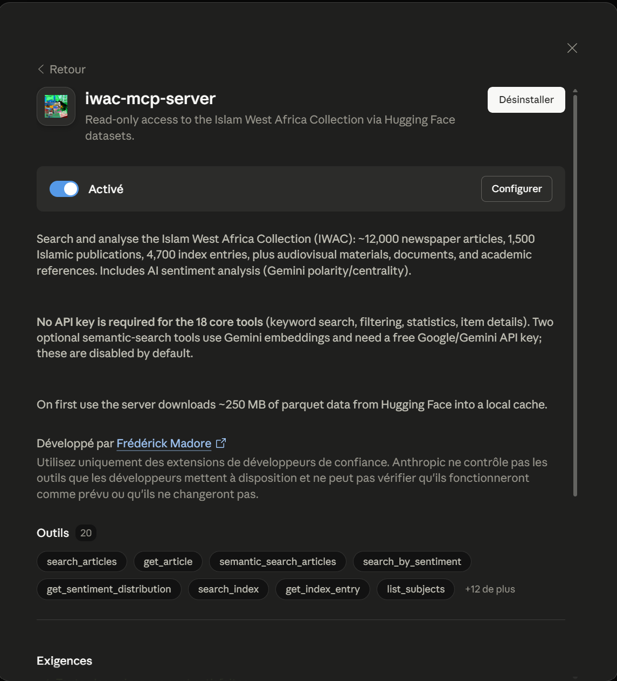
Installed as a Claude Desktop extension — read-only, no API key for the core tools.
One real question, and the skill runs the method live.
- Scopes the collection, then searches it in French
- Reads the strongest hits in full
- Answers with every claim linked to its IWAC record
Two saved runs below — press ↓
Saved run · secularism in Côte d'Ivoire
Brief — the default depth
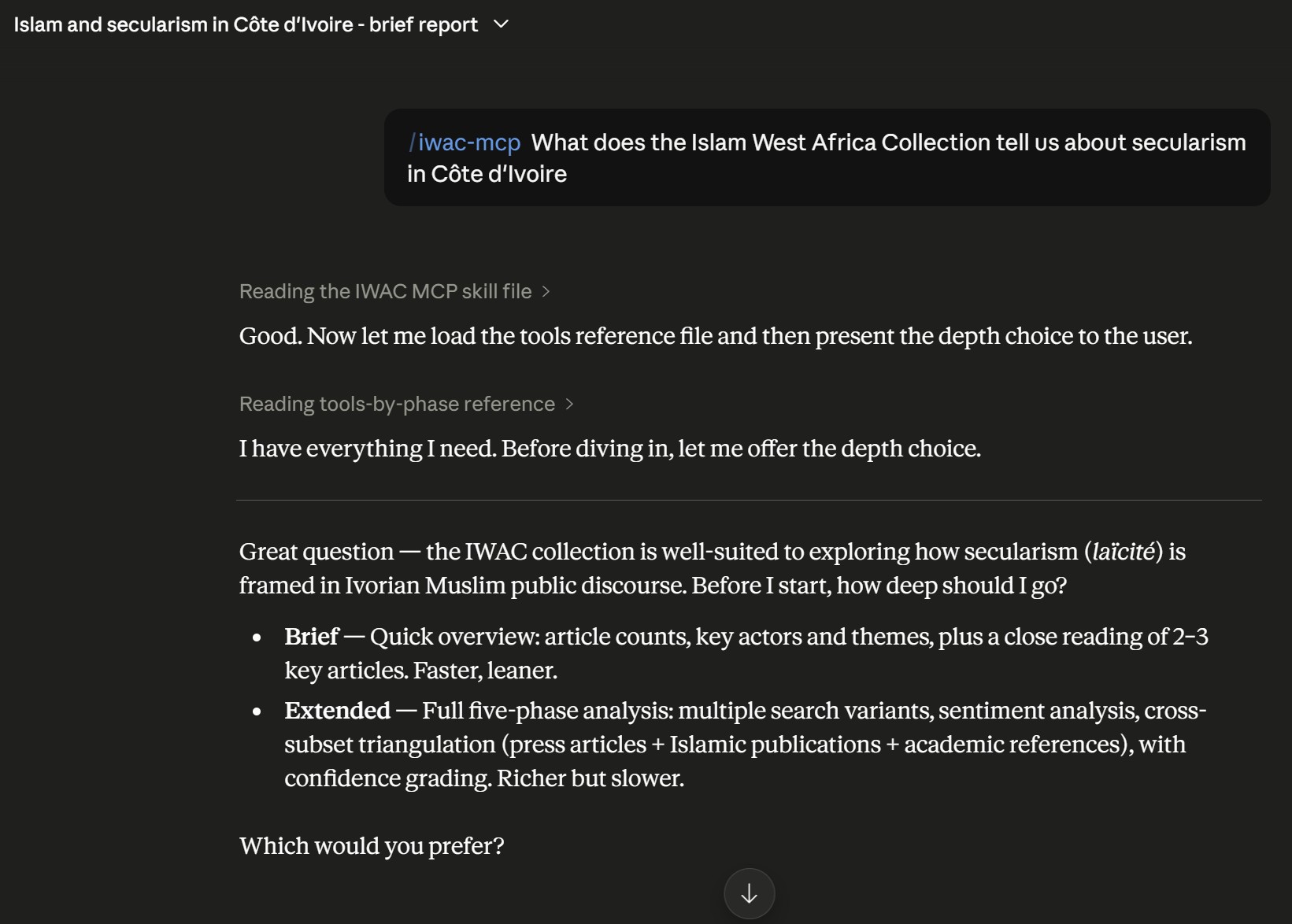
Claude Sonnet 4.6 · high effort
Saved run · Islam in Kpalimé, Togo
Extended — the full method
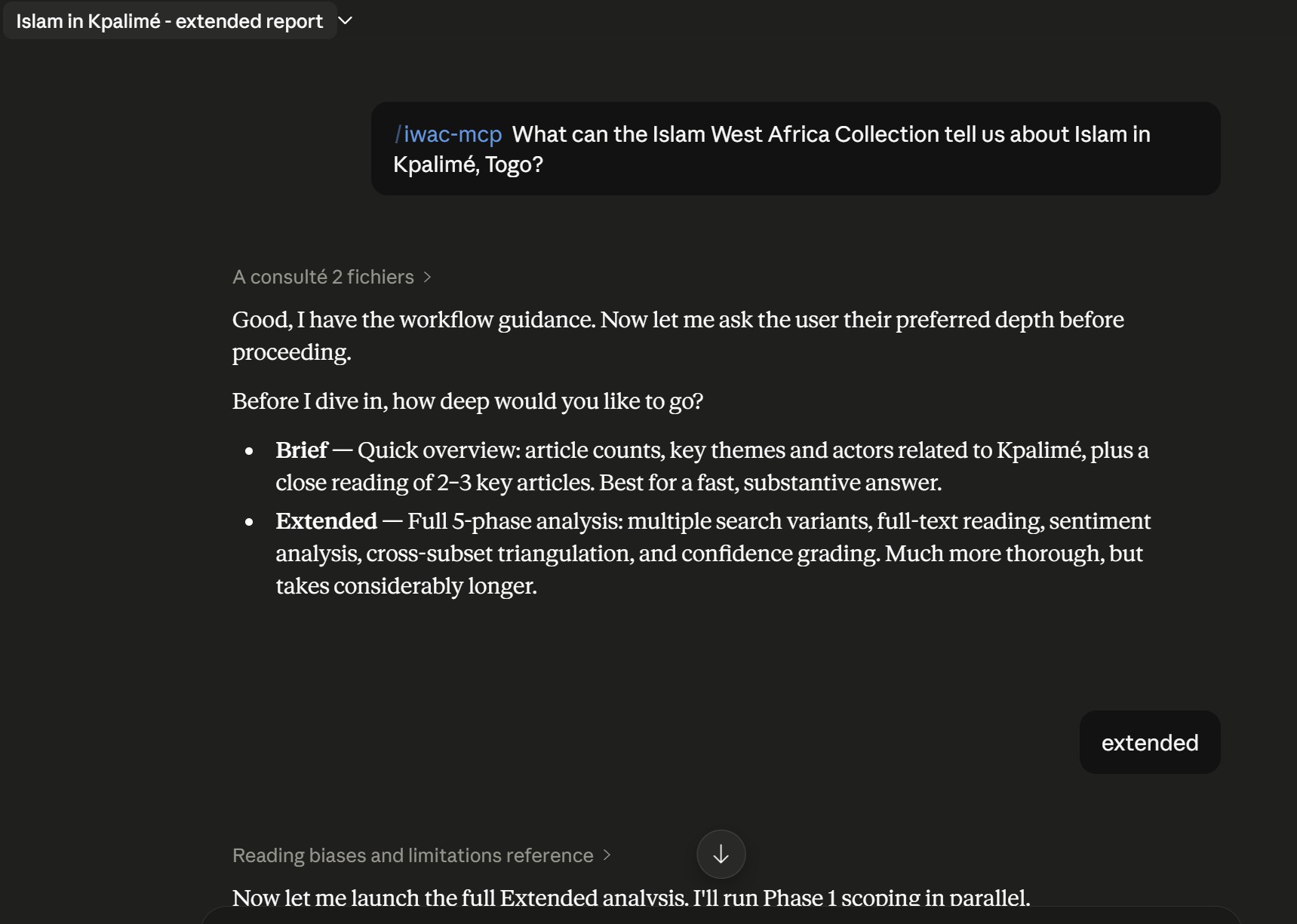
The same question we put to Gemini earlier, now answered from the IWAC.
The stakes
Whose infrastructure? African collections and AI extraction

39 of 43 heritage institutions hit by AI-bot traffic spikes (Weinberg, GLAM-E Lab, 2025); Wikimedia: 65% of its costliest traffic is bots. Read it ↗
- The default is extraction — public institutions and open-access labour subsidising commercial AI
- MCP, a third path — the collection stays put; the institution decides what the AI sees
Conclusion
A new way in for a wider public — but no replacement for archival research. It finds what you ask for, not what you weren’t looking for: the unexpected find that slow reading turns up.
Try it: connect Claude or ChatGPT to the collection — how-to on the IWAC AI-access page.
Next: a small open-source model on the server itself, answering on the website — no install, no account. github.com/fmadore/iwac-mcp-server
Scan for these slidesslides.frederickmadore.com